


예제 1:
Do File 1:
sysuse cancer, clear
la var died "Patient died"
la def ny 0 "No" 1 "Yes", modify
la val died ny
recode studytime (min/10 = 1 "10 or less months") (11/20 = 2 "11 to 20 months") (21/30 = 3 "21 to 30 months") (31/max = 4 "31 or more months") , gen(stime)
la var stime "To died or exp. end"
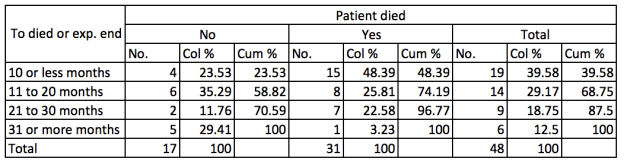
tabout stime died using table1.txt, cells(freq col cum) format(0 1) clab(No. Col_% Cum_%) replace해설1:
>tabout stime died using table1.txt, cells(freq col cum) format(0 2) clab(No. Col_% Cum_%) replace
- stime과 died 의 대하여 테이블을 만들어라 (tabout stime died)
- 만들어진 테이블은 table1.txt로 추출하라 (using table1.txt)
- 보여줄 항목은 “빈도수” “항목별 토탈 (즉 비율)” “누적비율” (cells(freq col cum))
- 첫번째 항목(freq)의 대해서는 소수점 없이 보여줄 것 + 두번째와 세번째 항복의 대해서는 소수점을 두자리까지 보여줄 것
(format (0 2))- 0c = 소수점 없이 세자릿수마다 “,” 찍기
- 1p = 소수점 첫자리 까지 보여주고 % 단위로 표기
- 만약 항목은 3개 인데 포멧에서는 2개만 설정 했다면 세번째 항목은 자동으로 두번째 항목과 동일
- 만약 항목은 3개 인데 포멧에서는 4개를 설정 했다면 네번째 설정은 무시됨.
- 보여줄 항목의 제목은 “No.” “Col_%” “Cum_%” 로 표기할 것
(clab(No. Col_% Cum_%)) - 만약 table1.txt라는 파일이 존재한다면 덮어쓰기 할 것 (replace)
예제2:
Do File 2:
sysuse nlsw88, clear
la var south "Location"
la def south 0 "Does not live in the South" 1 "Lives in the South"
la val south south
la var race "Race"
la def race 1 "White" 2 "Black" 3 "Other"
la val race race
la var collgrad "Education"
la def collgrad 0 "Not college graduate" 1 "College graduate"
la val collgrad collgrad
gen wt = 10 * runiform()
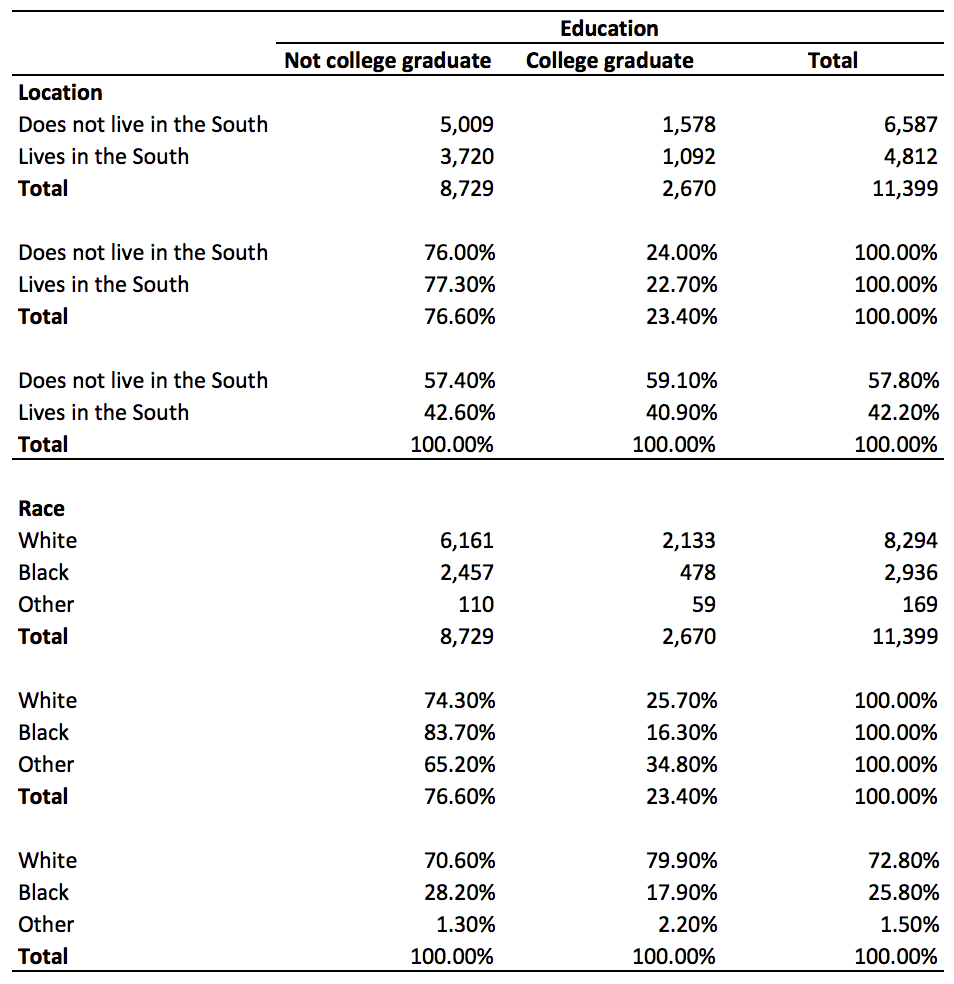
tabout south race collgrad [iw=wt] using table2.txt, cells(freq row col) format(0c 1p 1p) clab(_ _ _) layout(rb) h3(nil) replace해설2:
>tabout south race collgrad [iw=wt] using table2.txt, cells(freq row col) format(0c 1p 1p) clab(_ _ _) layout(rb) h3(nil) replace
- south, race와 collgrad의 대하여 테이블을 생성 (tabout south race collgrad)
- importance weight를 wt를 기준으로 주어라 ( [iw=wt] )
- iweights (Importance weights) are weights that indicate the “importance” of the observation in some vague sense. i weights have no formal statistical definition.
- fweights (frequency weights) are weights that indicate the number of duplicated observations
- pweights (sampling weights) are weights that denote the inverse of the probability that the observation is included because of the sampling design
- aweights (analytic weights) are weights that are inversely proportional to the variance of an observation.
- 만들어진 테이블은 table2.txt로 추출하라 (using table2.txt)
- 보여줄 항목은 “빈도수” “열별 토탈” “누적비율” (cells(freq row cum))
- 첫번째 항목은 소수점 없이 세자리마다 “,”로 표기 + 두번째 항목은 소수점 1자리와 % 기호 표기 + 세번째 항목은 소수점 1자리와 % 기호 표기 (format(0c 1p 1p))
- 항목별 제목 표시하지 말기 (clab(_ _ _))
- 레이아웃 정하기 (row block = rb) (column block = cb); (layout(rb))
- 테이블 헤딩 없애기
테이블 헤딩 사이즈 정하기 (h1~h3) 헤딩사이즈 표시는 html이나 tex로 추출할때만 적용가능
(h3(nil)) - 만약 table2.txt라는 파일이 존재한다면 덮어쓰기 할 것 (replace)